Open Source
agent-core(opens in new tab)
agent-core is a Python library providing common building blocks for creating AI agents. It uses InteropRouter as a unified interface for managing different AI model providers.

I am a Senior Applied Scientist in Microsoft’s Office of the CTO, advising executives on the future of AI, its progress, and its implications, grounded in science. I build demos, write technical content, and contribute to open source. Previously I worked on M365 Copilot, Microsoft Loop, and was a member of MAIDAP.
Prior to Microsoft, I was a data scientist at MassMutual and at ISO New England where at the latter I created forecasts to reliably predict energy demand for New England, which to my knowledge, is still used daily (yes, I’m proud of that).

Senior Applied Scientist
I started at Microsoft as an Applied Scientist in the MAIDAP program where I helped lead efforts to open-source a "Guided Conversations" agent framework as a demo in Semantic Kernel, create Loop Copilot, advance Copilot technology for Microsoft Federal, and automated cloud incident root cause analysis for Azure. Then as a member of the AI team for Microsoft Loop, I helped develop features for Copilot Pages such as being able to edit pages from Copilot Chat. And finally I am in my current role in the Office of the CTO.

Data Scientist
I was a Data Scientist at MassMutual as a member of the Data Science Development Program, working on various projects in Investment & Finance and Cybersecurity & Fraud. I completed my Master's in CS at this time as well.


M.S. Computer Science

Data Science Intern
I was an intern in the Day-Ahead Forecasting and Related Markets team at ISO New England. I worked on a variety of projects, including a machine learning system to forecast day ahead energy demand. As of August 2021, it is being used as part of daily electric grid operations for the entire New England electric grid!
B.S. Computer Science
agent-core is a Python library providing common building blocks for creating AI agents. It uses InteropRouter as a unified interface for managing different AI model providers.
agent-tui is a terminal user interface for AI agents built with Textual. It is built on top of agent-core and InteropRouter.
InteropRouter is designed to seamlessly interoperate between the most common AI providers at a high level of quality. It uses the OpenAI Responses API types as a common denominator for inputs and outputs, allowing you to switch between providers with minimal code changes.

Eval Recipes is a library dedicated to making it easier to keep up with the state-of-the-art in evaluating AI agents. It currently has two main components: a benchmarking harness for evaluating CLI agents (GitHub Copilot CLI, Claude Code, etc) on real-world tasks via containers and an online evaluation framework for LLM chat assistants. The common thread between these components is the concept of recipes which are a mix of code and LLM calls to achieve a desired tradeoff between flexibility and quality.
Amplifier brings AI assistance to your command line with a modular, extensible architecture. My contributions include evaluation and building out core provider modules.
US Patent Application US-20250378320-A1 - "GENERATIVE AGENT GUIDED CONVERSATIONS FOR ARTIFACT COMPLETION" (Pending)

A game where you knock pieces of trash into the air and collect them in your dump truck. Avoid the obstacles and get a high score! Built for Ludum Dare 58.
The Document Assistant is an AI assistant in Microsoft's Semantic Workbench focused on being easy to use for everyone with a core feature being reliable document creation and editing, grounded in all of your context across files and the conversation.
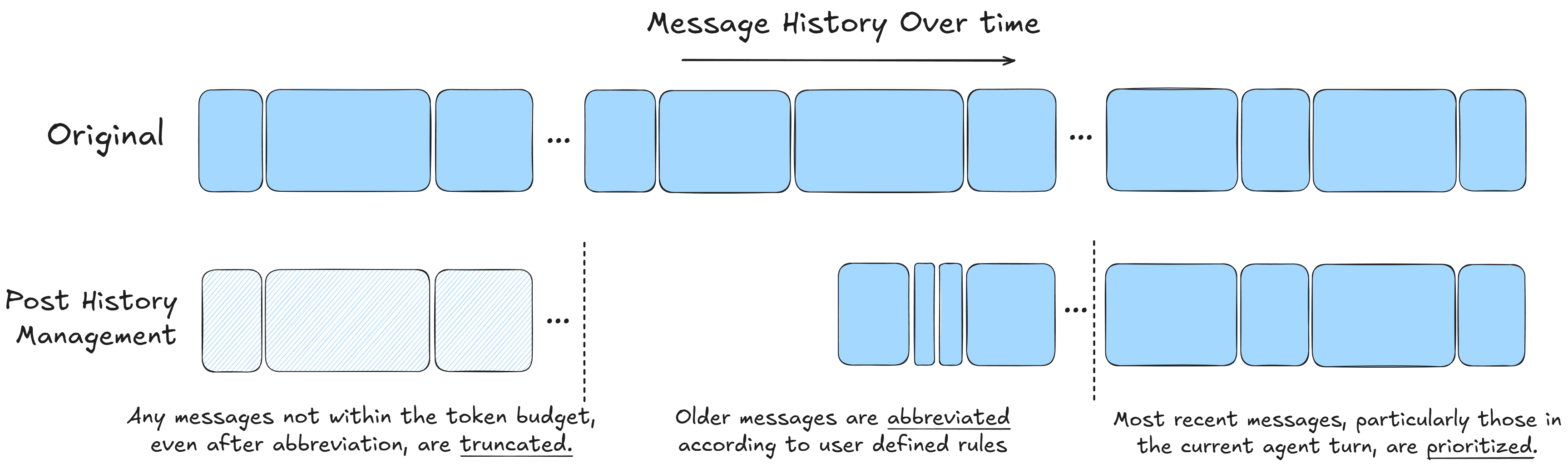
The Chat Context Toolkit is a Python library, currently a part of Microsoft's Semantic Workbench designed to efficiently manage context for most AI agents. Read more on LinkedIn.
The chat context toolkit provides these three core, modular components:
Message History Management: Applies context engineering techniques to ensure that messages fit within a token budget.
Archive: A task for archiving and processing chunks of the message history that may no longer fit within a token budget to ensure older data can still be considered.
Virtual Filesystem: Creates a common abstraction for LLMs to read, edit, and explore files coming from a variety of disparate sources.

TinkerTasker is an open-source and local first CLI agent similar to the likes of Claude Code and Codex. It's a project that allowed me to focus on teaching about important AI tech like the Model Context Protocol (MCP), while also still having unique aspects: namely it is fully hackable by being simple and modular and I developed it to run completely locally without any APIs at all.
not-again-ai is a collection of various building blocks that come up over and over again when developing AI products. The key goals of this package are to have simple, yet flexible interfaces and to minimize dependencies.
US Patent Application US-20250131289-A1 - "Knowledge Graph Extraction" (Pending)

DIGGITY DIGGITY DIGGITY ITS TIME TO GO RACING IN THE DEPTHS OF MOLE HILLS!!!
You are a mole who is in D.O.W.N.S.P.E.E.D. (Digging Operators with Notable Speed Pioneering Earth Excavation & Depth). Your goal is to win the championship and take home the cup! Built for Ludum Dare 57.

ReDoodle is a "daily" web puzzle game where you are given a starting image, and your goal is to transform it into a goal image through a series of prompts.
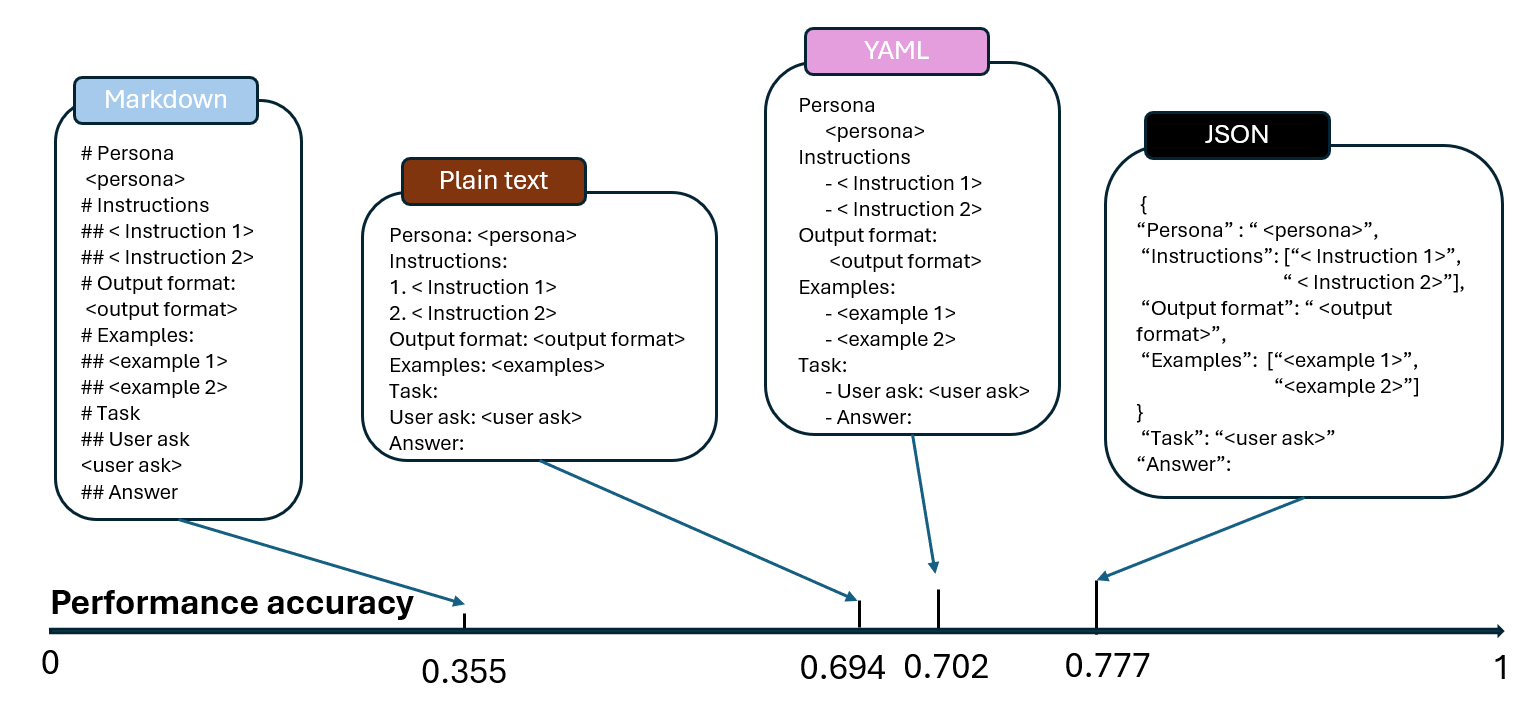
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X Wang, Sadid Hasan
In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.

Use your tiny bacteria to fight foes and grow into something bigger than the sum of your tiny parts! Built for Ludum Dare 56.
Guided Conversations is a framework in Semantic Kernel for building AI agents that lead goal-driven conversations with defined constraints, where the agent initiates dialogue, follows a structured conversation flow, exercises judgment to stay on track, and generates artifacts like notes and forms throughout the interaction. Common use cases include teaching scenarios, customer service interactions, and any situation where a "creator" defines conversation goals and collects information semi-autonomously through an AI assistant.

Soul Food is a game where you summon monsters to satiate your hungry customers! Built for Ludum Dare 55.

Societies around the galaxy are running out of space. You are the last hope to delay the stranding. Deliver pods from overpopulated planets (denoted with a red icon) to growing planets (denoted with blue icons). Get a high score before all the planets run out of space! Built for Ludum Dare 54.

Enter a realm of magical deliveries in this fantasy RPG management game. Assemble your elite team of couriers and strive to thrive in the cutthroat world of delivery services. Built for Ludum Dare 53.

Barn Busters is a physics based tower defense game inspired by Fall Guys, built for Ludum Dare 52. Placed in the top 20 for both innovation and fun and in the top 10% overall out of over 1,000 submissions.

Big Block Mode is another take on the classic tetromino puzzler, built for Ludum Dare 51. Placed 67th for Innovation and in the top 20% overall.
David Koleczek, Alex Scarlatos, Siddha Karakare, Preshma Linet Pereira
The 16th International Workshop on Semantic Evaluation (SemEval-2022)
Patronizing and condescending language (PCL) is everywhere, but rarely is the focus on its use by media towards vulnerable communities. Accurately detecting PCL of this form is a difficult task due to limited labeled data and how subtle it can be. In this paper, we describe our system for detecting such language which was submitted to SemEval 2022 Task 4: Patronizing and Condescending Language Detection. Our approach uses an ensemble of pre-trained language models, data augmentation, and optimizing the threshold for detection. Experimental results on the evaluation dataset released by the competition hosts show that our work is reliably able to detect PCL, achieving an F1 score of 55.47% on the binary classification task and a macro F1 score of 36.25% on the fine-grained, multi-label detection task.

Cabbage Crashers is a cabbage farming simulation game built for Ludum Dare 50.
Weihao Tan, David Koleczek, Siddhant Pradhan, Nicholas Perello, Vivek Chettiar, Nan Ma, Aaslesha Rajaram, Vishal Rohra, Soundar Srinivasan, H M Sajjad Hossain, Yash Chandak
Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022)
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often also be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions. We show that not only does our method outperform the existing baseline, but also eliminates the need to manually tune a black-box hyperparameter for controlling the level of assistance. Code available at: https://github.com/DavidKoleczek/human_marl
Weihao Tan, David Koleczek, Siddhant Pradhan, Nicholas Perello, Vivek Chettiar, Nan Ma, Aaslesha Rajaram, Vishal Rohra, Soundar Srinivasan, H M Sajjad Hossain, Yash Chandak
HumanAI workshop @ Thirty-eighth International Conference on Machine Learning (ICML 2021)
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions.
An NLP-powered web application to automatically curate tweets from the machine learning community on Twitter. The content was also reposted on Twitter.
agent-core is a Python library providing common building blocks for creating AI agents. It uses InteropRouter as a unified interface for managing different AI model providers.
agent-tui is a terminal user interface for AI agents built with Textual. It is built on top of agent-core and InteropRouter.
InteropRouter is designed to seamlessly interoperate between the most common AI providers at a high level of quality. It uses the OpenAI Responses API types as a common denominator for inputs and outputs, allowing you to switch between providers with minimal code changes.
Eval Recipes is a library dedicated to making it easier to keep up with the state-of-the-art in evaluating AI agents. It currently has two main components: a benchmarking harness for evaluating CLI agents (GitHub Copilot CLI, Claude Code, etc) on real-world tasks via containers and an online evaluation framework for LLM chat assistants. The common thread between these components is the concept of recipes which are a mix of code and LLM calls to achieve a desired tradeoff between flexibility and quality.
Amplifier brings AI assistance to your command line with a modular, extensible architecture. My contributions include evaluation and building out core provider modules.
US Patent Application US-20250378320-A1 - "GENERATIVE AGENT GUIDED CONVERSATIONS FOR ARTIFACT COMPLETION" (Pending)
A game where you knock pieces of trash into the air and collect them in your dump truck. Avoid the obstacles and get a high score! Built for Ludum Dare 58.
The Document Assistant is an AI assistant in Microsoft's Semantic Workbench focused on being easy to use for everyone with a core feature being reliable document creation and editing, grounded in all of your context across files and the conversation.
The Chat Context Toolkit is a Python library, currently a part of Microsoft's Semantic Workbench designed to efficiently manage context for most AI agents. Read more on LinkedIn.
The chat context toolkit provides these three core, modular components:
Message History Management: Applies context engineering techniques to ensure that messages fit within a token budget.
Archive: A task for archiving and processing chunks of the message history that may no longer fit within a token budget to ensure older data can still be considered.
Virtual Filesystem: Creates a common abstraction for LLMs to read, edit, and explore files coming from a variety of disparate sources.
TinkerTasker is an open-source and local first CLI agent similar to the likes of Claude Code and Codex. It's a project that allowed me to focus on teaching about important AI tech like the Model Context Protocol (MCP), while also still having unique aspects: namely it is fully hackable by being simple and modular and I developed it to run completely locally without any APIs at all.
not-again-ai is a collection of various building blocks that come up over and over again when developing AI products. The key goals of this package are to have simple, yet flexible interfaces and to minimize dependencies.
US Patent Application US-20250131289-A1 - "Knowledge Graph Extraction" (Pending)
DIGGITY DIGGITY DIGGITY ITS TIME TO GO RACING IN THE DEPTHS OF MOLE HILLS!!!
You are a mole who is in D.O.W.N.S.P.E.E.D. (Digging Operators with Notable Speed Pioneering Earth Excavation & Depth). Your goal is to win the championship and take home the cup! Built for Ludum Dare 57.
ReDoodle is a "daily" web puzzle game where you are given a starting image, and your goal is to transform it into a goal image through a series of prompts.
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X Wang, Sadid Hasan
In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.
Use your tiny bacteria to fight foes and grow into something bigger than the sum of your tiny parts! Built for Ludum Dare 56.
Guided Conversations is a framework in Semantic Kernel for building AI agents that lead goal-driven conversations with defined constraints, where the agent initiates dialogue, follows a structured conversation flow, exercises judgment to stay on track, and generates artifacts like notes and forms throughout the interaction. Common use cases include teaching scenarios, customer service interactions, and any situation where a "creator" defines conversation goals and collects information semi-autonomously through an AI assistant.
Soul Food is a game where you summon monsters to satiate your hungry customers! Built for Ludum Dare 55.
Societies around the galaxy are running out of space. You are the last hope to delay the stranding. Deliver pods from overpopulated planets (denoted with a red icon) to growing planets (denoted with blue icons). Get a high score before all the planets run out of space! Built for Ludum Dare 54.
Enter a realm of magical deliveries in this fantasy RPG management game. Assemble your elite team of couriers and strive to thrive in the cutthroat world of delivery services. Built for Ludum Dare 53.
Barn Busters is a physics based tower defense game inspired by Fall Guys, built for Ludum Dare 52. Placed in the top 20 for both innovation and fun and in the top 10% overall out of over 1,000 submissions.
Big Block Mode is another take on the classic tetromino puzzler, built for Ludum Dare 51. Placed 67th for Innovation and in the top 20% overall.
David Koleczek, Alex Scarlatos, Siddha Karakare, Preshma Linet Pereira
The 16th International Workshop on Semantic Evaluation (SemEval-2022)
Patronizing and condescending language (PCL) is everywhere, but rarely is the focus on its use by media towards vulnerable communities. Accurately detecting PCL of this form is a difficult task due to limited labeled data and how subtle it can be. In this paper, we describe our system for detecting such language which was submitted to SemEval 2022 Task 4: Patronizing and Condescending Language Detection. Our approach uses an ensemble of pre-trained language models, data augmentation, and optimizing the threshold for detection. Experimental results on the evaluation dataset released by the competition hosts show that our work is reliably able to detect PCL, achieving an F1 score of 55.47% on the binary classification task and a macro F1 score of 36.25% on the fine-grained, multi-label detection task.
Cabbage Crashers is a cabbage farming simulation game built for Ludum Dare 50.
Weihao Tan, David Koleczek, Siddhant Pradhan, Nicholas Perello, Vivek Chettiar, Nan Ma, Aaslesha Rajaram, Vishal Rohra, Soundar Srinivasan, H M Sajjad Hossain, Yash Chandak
Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022)
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often also be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions. We show that not only does our method outperform the existing baseline, but also eliminates the need to manually tune a black-box hyperparameter for controlling the level of assistance. Code available at: https://github.com/DavidKoleczek/human_marl
Weihao Tan, David Koleczek, Siddhant Pradhan, Nicholas Perello, Vivek Chettiar, Nan Ma, Aaslesha Rajaram, Vishal Rohra, Soundar Srinivasan, H M Sajjad Hossain, Yash Chandak
HumanAI workshop @ Thirty-eighth International Conference on Machine Learning (ICML 2021)
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions.
An NLP-powered web application to automatically curate tweets from the machine learning community on Twitter. The content was also reposted on Twitter.